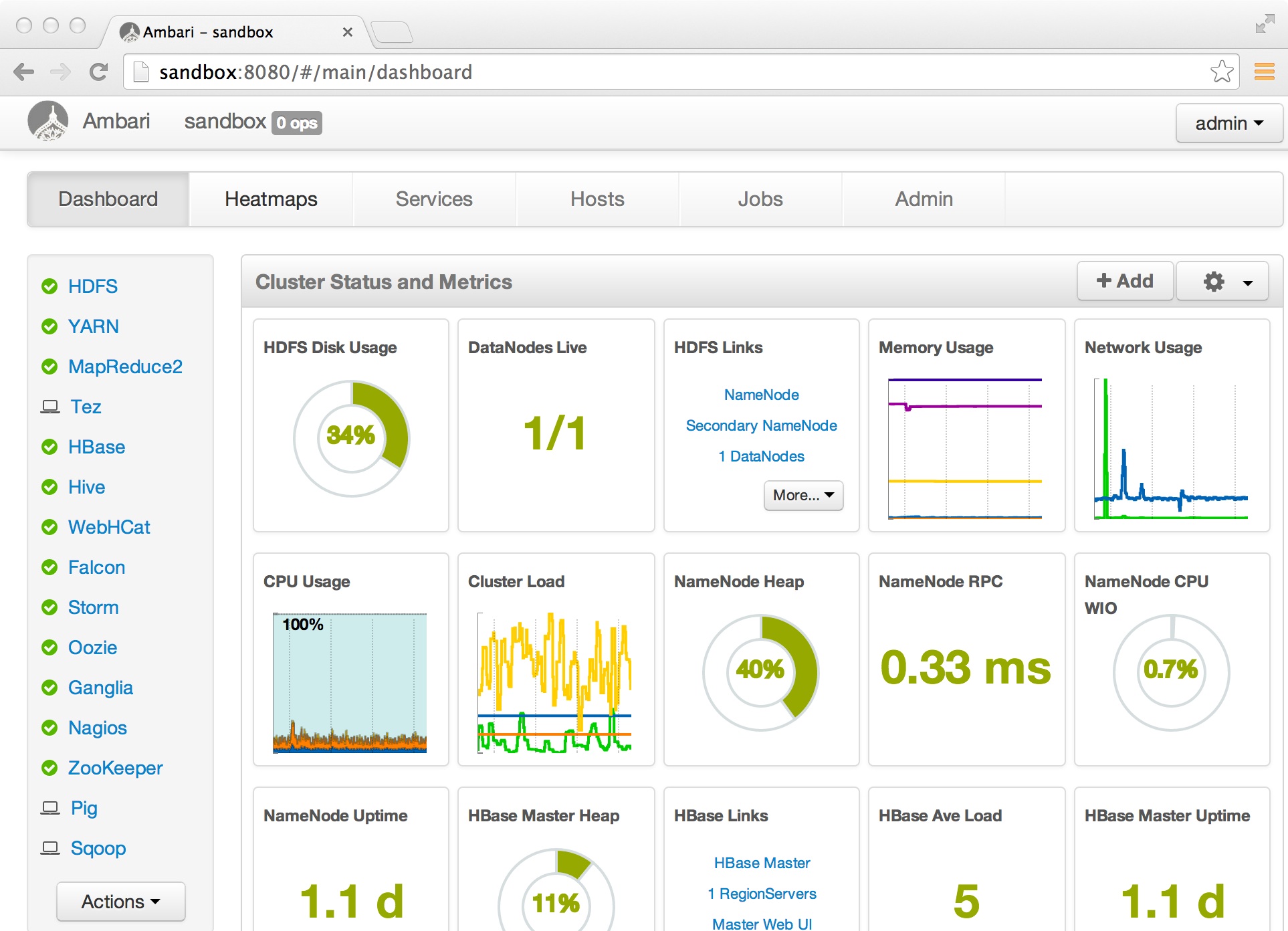
1. What is Hadoop framework?
Ans: Hadoop is an open source framework which is written in java by apache software foundation.
This framework is used to write software application which requires to process vast amount of data (It
could handle multi tera bytes of data). It works in-parallel on large clusters which could have 1000 of
computers (Nodes) on the clusters. It also process data very reliably and fault-tolerant manner. See
the below image how does it looks.
2. On What concept the Hadoop framework works?
Ans: It works on MapReduce, and it is devised by the Google.
3. What is MapReduce?
Ans: Map reduces is an algorithm or concept to process Huge amount of data in a faster way. As per
its name you can divide it Map and Reduce.
• The main MapReduce job usually splits the input data-set into independent chunks. (Big data sets in
the multiple small datasets)
• Reduce Task: And the above output will be the input for the reduce tasks, produces the final result.
Your business logic would be written in the Mapped Task and Reduced Task. Typically both the input
and the output of the job are stored in a file-system (Not database). The framework takes care of
scheduling tasks, monitoring them and re-executes the failed tasks.
4. What is compute and Storage nodes?
Ans: Compute Node: This is the computer or machine where your actual business logic will be
executed.
Storage Node: This is the computer or machine where your file system resides to store the processing
data. In most of the cases compute node and storage node would be the same machine.
5. How does master slave architecture in the Hadoop?
Ans: the MapReduce framework consists of a single master Job Tracker and multiple slaves, each
cluster-node will have one Task Tracker.The master is responsible for scheduling the jobs' component tasks on the slaves, monitoring
them and re-executing the failed tasks. The slaves execute the tasks as directed by the master.
6. How does a Hadoop application look like or their basic components?
Ans: Minimally a Hadoop application would have following components.
• Input location of data
• Output location of processed data.
• A map task.
• A reduced task.
• Job configuration
The Hadoop job client then submits the job (jar/executable etc.) and configuration to the Job Tracker
which then assumes the responsibility of distributing the software/configuration to the slaves,
scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
7. Explain how input and output data format of the Hadoop framework?
Ans: The MapReduce framework operates exclusively on pairs, that is, the framework views the
input to the job as a set of pairs and produces a set of pairs as the output of the job, conceivably of
different types. See the flow mentioned below (input) -> map -> -> combine/sorting -> -> reduce ->
(output)
8. What are the restriction to the key and value class?
Ans: The key and value classes have to be serialized by the framework. To make them serializable
Hadoop provides a Writable interface. As you know from the java itself that the key of the Map
should be comparable, hence the key has to implement one more interface Writable Comparable.
9. Explain the Word Count implementation via Hadoop framework?
Ans: We will count the words in all the input file flow as below
• Input
Assume there are two files each having a sentence Hello World Hello World (In file 1) Hello World
Hello World (In file 2)
• Mapper: There would be each mapper for the a file
For the given sample input the first map output:
< Hello, 1>< World, 1>
< Hello, 1>
< World, 1>
The second map output:
< Hello, 1>
< World, 1>
< Hello, 1>
< World, 1>
• Combiner/Sorting (This is done for each individual map)
So output looks like this
The output of the first map:
< Hello, 2>
< World, 2>
The output of the second map:
< Hello, 2>
< World, 2>
• Reducer:
• Output
It sums up the above output and generates the output as below
< Hello, 4>
< World, 4>
Final output would look like
Hello 4 times
World 4 times10. Which interface needs to be implemented to create Mapper and Reducer for the Hadoop?
Ans: org.apache.hadoop.mapreduce.Mapper org.apache.hadoop.mapreduce.Reducer
11. What Mapper does?
Ans: Maps are the individual tasks that transform input records into intermediate records. The
transformed intermediate records do not need to be of the same type as the input records. A given
input pair may map to zero or many output pairs.
12. What is the Input Split in map reduce software?
Ans: An Input Split is a logical representation of a unit (A chunk) of input work for a map task; e.g., a
filename and a byte range within that file to process or a row set in a text file.
13. What is the Input Format?
Ans: The Input Format is responsible for enumerate (itemize) the Input Split, and producing a Record
Reader which will turn those logical work units into actual physical input records.
14. Where do you specify the Mapper Implementation?
Ans: Generally mapper implementation is specified in the Job itself.
15. How Mapper is instantiated in a running job?
Ans: The Mapper itself is instantiated in the running job, and will be passed a
Map Context object which it can use to configure itself
16. Which are the methods in the Mapper interface?
Ans: the Mapper contains the run () method, which call its own setup () method only once, it also call
a map () method for each input and finally calls it cleanup () method. All above methods you can
override in your code.
17. What happens if you don’t override the Mapper methods and keep them as it is?
Ans: If you do not override any methods (leaving even map as-is), it will act as the identity function,
emitting each input record as a separate output.
18. What is the use of Context object?
Ans: The Context object allows the mapper to interact with the rest of the Hadoop system. It
Includes configuration data for the job, as well as interfaces which allow it to emit output.19. How can you add the arbitrary key-value pairs in your mapper?
Ans: You can set arbitrary (key, value) pairs of configuration data in your Job, e.g. with
Job.getConfiguration ().set ("myKey", "myVal"), and then retrieve this data in your mapper with
context.getConfiguration ().get ("myKey"). This kind of functionality is typically done in the Mapper's
setup () method.
20. How does Mapper’s run () method works?
Ans: The Mapper. Run () method then calls map (KeyInType, ValInType, Context) for each key/value
pair in the Input Split for that task
21. Which object can be used to get the progress of a particular job?
Ans: Context
22. What is next step after Mapper or MapTask?
Ans: The output of the Mapper is sorted and Partitions will be created for the output. Number of
partition depends on the number of reducer.
23. How can we control particular key should go in a specific reducer?
Ans: Users can control which keys (and hence records) go to which Reducer by implementing a custom
Partitioner.
24. What is the use of Combiner?
Ans: It is an optional component or class, and can be specify via Job.setCombinerClass (Class Name),
to perform local aggregation of the intermediate outputs, which helps to cut down the amount of
data transferred from the Mapper to the Reducer.
25. How many maps are there in a particular Job?
Ans: the number of maps is usually driven by the total size of the inputs, that is, the total number of
blocks of the input files.
Generally it is around 10-100 maps per-node. Task setup takes awhile, so it is best if the maps take at
least a minute to execute.
Suppose, if you expect 10TB of input data and have a block size of 128MB, you'll end up with 82,000
maps, to control the number of block you can use the mapreduce.job.maps parameter (which only
provides a hint to the framework). Ultimately, the number of tasks is controlled by the number of
splits returned by the InputFormat.getSplits () method (which you can override).
26. What is the Reducer used for?Ans: Reducer reduces a set of intermediate values which share a key to a (usually smaller) set of
values. The number of reduces for the job is set by theuser via Job.setNumReduceTasks (int).
27. Explain the core methods of the Reducer?
Ans: The API of Reducer is very similar to that of Mapper, there's a run() method that receives a
Context containing the job's configuration as well as interfacing methods that return data from the
reducer itself back to the framework. The run() method calls setup() once, reduce() once for each
key associated with the reduce task, and cleanup() once at the end. Each of these methods can
access the job's configuration data by using Context.getConfiguration ().
As in Mapper, any or all of these methods can be overridden with custom implementations. If none of
these methods are overridden, the default reducer operation is the identity function; values are
passed through without further processing.
The heart of Reducer is it’s reduce () method. This is called once per key; the second argument is an
Iterable which returns all the values associated with that key.
28. What are the primary phases of the Reducer?
Ans: Shuffle, Sort and Reduce
29. Explain the shuffle?
Ans: Input to the Reducer is the sorted output of the mappers. In this phase the framework fetches
the relevant partition of the output of all the mappers, via HTTP.
30. Explain the Reducer’s Sort phase?
Ans: The framework groups Reducer inputs by keys (since different mappers may have output the
same key) in this stage. The shuffle and sort phases occur simultaneously; while map-outputs are
being fetched they are merged (It is similar to merge-sort).