This is the second tutorial to enable you as a Java developer to learn about Cascading and Hortonworks Data Platform (HDP). Other tutorials are:
In this tutorial, you will do the following:
- Install Hortonworks Sandbox, a single-node cluster
- Code a simple Java log parsing application using Cascading SDK
- Build the single unit of execution, the jar file, using the gradle build tool
- Deploy the jar file onto to the Sandbox
- Examine the resulting MapReduce Jobs
- View the output stored as an HDSF file.
This example code is derived from Concurrent Inc.’s training class by Alexis Roos (@alexisroos). It demonstrates the simplicity of using Cascading Java Framework to write MapReduce Jobs, without using the actual MapReduce API, to parse a large file for analysis. Even though the example merely sorts the top ten IP’s visited, its efficacy and usage is far more powerful. Nonetheless, it introduces its potential and its simplicity.
Step 1: Downloading and installing HDP 2.1 Sandbox
- Download and install HDP 2.1 Sandbox
- Familiarize yourself with the navigation on the Linux virtual host through a shell window
- Login into your Linux Sandbox as root (password is hadoop)
ssh -p 2222 root@127.0.0.1su guest
Step 2: Downloading and installing Gradle
cd /home/guestwget https://services.gradle.org/distributions/gradle-1.12-all.zipunzip gradle-1.12-all.zipexport PATH=$PATH:/home/guest/gradle-1.12/bin
Step 3: Downloading sources and log data file
git clone git://github.com/dmatrix/examples.gitcd /home/guest/examples/dataprocessingwget http://files.concurrentinc.com/training/NASA_access_log_Aug95.txt
Step 4: Building the single unit of execution
cd /home/guest/examples/dataprocessinggradle clean jar
Step 5: Running the jar on Sandbox
- create a logs directory in HDFS
hdfs dfs -mkdir /user/guest/logs
- create an output directory in HDFS
hdfs dfs –mkdir /user/guest/output
- copy the log file from the local filesystem to the HDFS logs directory
hdfs dfs -copyFromLocal ./NASA_access_log_Aug95.txt /user/guest/logs
- Finally, run the Cascading application on the Sandbox, the single-node HDP cluster
hadoop jar ./build/libs/dataprocessing.jar /user/guest/logs /user/guest/output/logs
This run should create the following output:
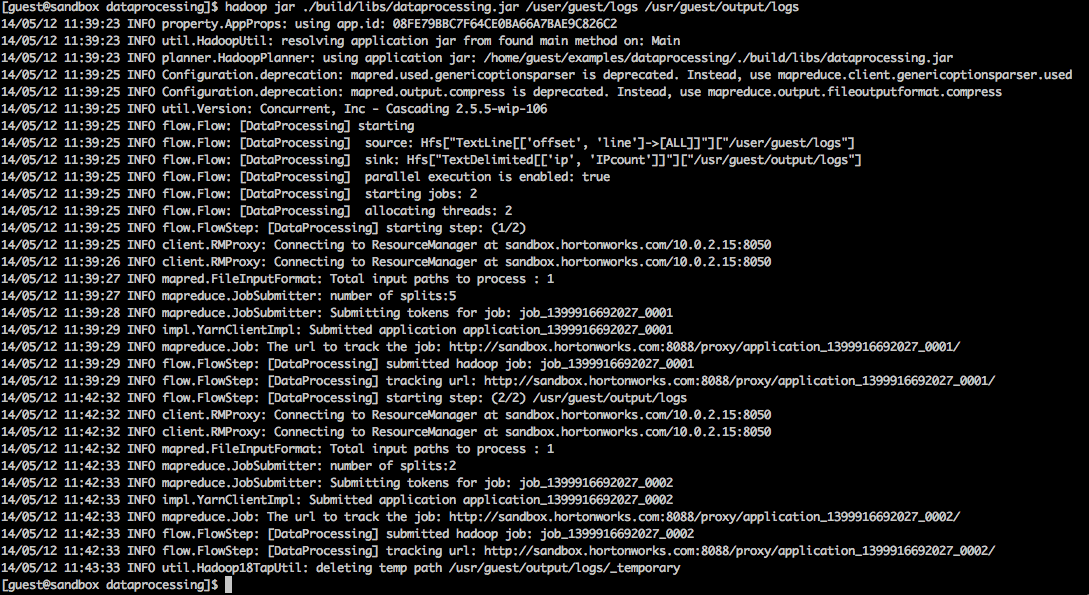
Tracking the MapReduce Jobs on the Sandbox
Once the job is submitted (or running), you can visually track its progress from the Sandbox Hue’s Job Browser. By default, it will display all jobs submitted by the user hue; filter by the user guest.
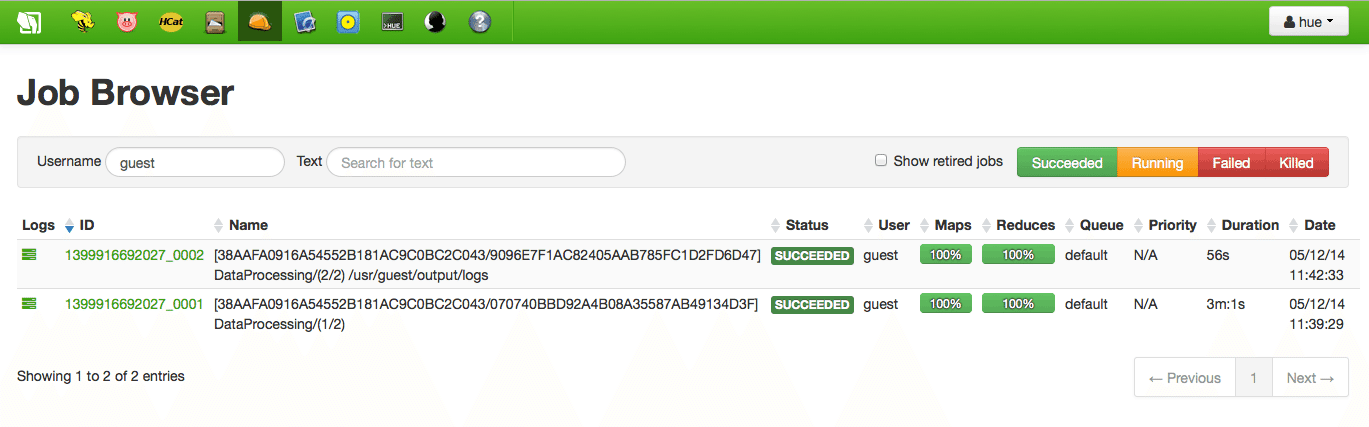 You can drill down on any links to explore further details about the Map Reduce jobs running in their respective YARN containers. For example, clicking on one of the job ids will show all the maps and reduces tasks created.
You can drill down on any links to explore further details about the Map Reduce jobs running in their respective YARN containers. For example, clicking on one of the job ids will show all the maps and reduces tasks created.Viewing the Log Parsing Output
When the job is finished, the 10 IP addresses are written as an HDFS file part-00000. Use the Sandbox Hue’s File Browser to navigate to the HDFS directory, /user/guest/output/logs, and view its contents.

Voila! You have written a Cascading log processing application, executed it on the Hortonworks HDP Sandbox, and perused the respective MapReduce jobs and the output generated.
In the next tutorial, we will examine how you to use Cascading Driven to discover in-depth information on the Flow (including logical, physical, and performance views).